| Table of Contents |
|---|
...
This Privacy Policy explains what information Lizard Brain UG ("Vendor") collect about you and why, what we do with that information and how we handle the content you place in Planning Poker ("Add-On"). It is fully compliant with the Atlassian Privacy Policy.
Scope of Privacy Policy
This Privacy Policy applies to the information that we obtain through your use of the "Planning Poker". By using "Planning Poker" you consent to the collection, processing, storage, disclosure and other uses described in this Privacy Policy.
Definitions
Add-On: a bundle of code, resources and configuration files that can be used with an Atlassian product to add new functionality or to change the behavior of that product's existing features, which is the "Planning Poker" in the scope of this document.
Content: any information or data that you upload, submit, post, create, transmit, store or display in an Atlassian Service.
...
Changes to our Privacy Policy
We may change this Privacy Policy from time to time. If we make any changes, we will notify you by revising the "Effective Starting" date at the top of this Privacy Policy.
If you disagree with any changes to this Privacy Policy, you will need to stop using Atlassian Services and deactivate your account(s), as outlined below.
...
Information we collect from your use of Add-On
Web Logs
As is true with most websites and services delivered over the Internet, we gather certain information and store it in log files when you interact with the Add-On. This information includes internet protocol (IP) addresses as well as browser type, internet service provider, URLs of referring/exit pages, operating system, date/time stamp, information you search for, locale and language preferences, identification numbers associated with your Devices, your mobile carrier, and system configuration information, the URLs you accessed (and therefore included in our log files) include usernames as well as elements of Content (such as Jira project names, project keys, status names, and JQL filters) as necessary for the Add-On to perform the requested operations. Occasionally, we connect Personal Information to information gathered in our log files as necessary to improve Add-On Services for individual customers. In such a case, we would treat the combined Information in accordance with this privacy policy.
Analytics Information
We collect analytics information when you use our Add-On to help us improve our products and services. This analytics information consists of the feature and function of the Add-On being used, the associated license identifier (SEN) and domain name, the username and user data available from the Jira REST API. The analytics information we collect includes elements of Content related to the function the user is performing. As such, the analytics information we collect may include Personal Information or sensitive business information that the user has included in Content that the user chose to upload, submit, post, create, transmit, store or display in the Add-On.
...
These IDs are used for the following:
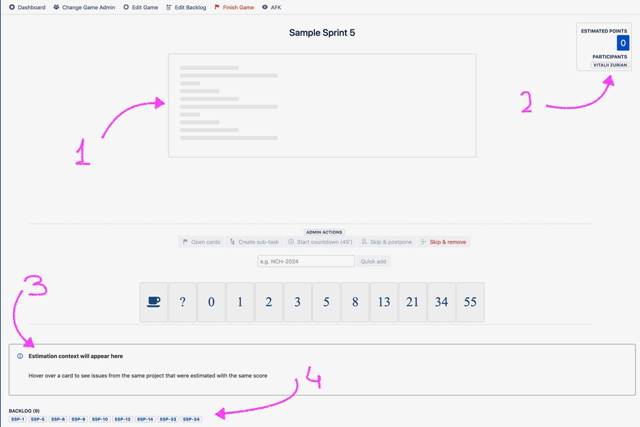
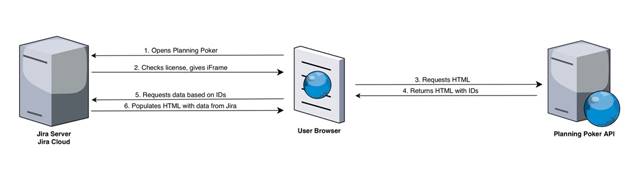
- When the user loads the game from the Planning Poker API, they receive all relevant Game Session information represented by the IDs (issue IDs and user IDs). After that, JavaScript code in the user's browser executes a call to the Jira REST API to fetch all the information about the Issue and to populate it into the Number 1 on the screenshot. This communication happens only between the user browser and the Jira REST API.
- Same logic applies to the population of Game Players section — Number 2 on the screenshot
- Estimation context (Number 3) is basically just a search from the current user browser against the Jira REST API
- Estimation Backlog and Archive (Number 4) is represented by the issue IDs. When a used clicks on any of the IDs, the required data is pulled via the current user browser JavaScript from the Jira REST API (no outgoing requests)
There are also other views in the Planning Poker where the issues information is displayed (such as Estimation Backlog Details), but the logic there is the same as described above.
Therefore, the only outgoing information from Jira is the anonymised IDs, the rest happens between the user browser and Jira REST API (within the same network).
Rough illustration of this communication is attached below.